AI Supremacy Showdown: The U.S. vs. China - Results are In!
The race to dominate AI is intensifying and the AI war between USA and Chinese is irreversible. Large Language Models (LLM) models have become cornerstones of artificial intelligence, driving breakthroughs in natural language processing, multimodal applications, and industry-specific solutions. The United States and China, as global AI powerhouses, are pushing the boundaries of Large Language Model (LLM) development, each bringing unique strengths to the table. This slice dives into the latest iterations of leading LLMs from both nations, comparing their capabilities and characteristics across multiple dimensions. Whether you're a tech enthusiast, AI developer, or business professional, this analysis offers a window into the state of AI innovation as of February 24, 2025.

USA AI Models
GPT-4o (OpenAI)
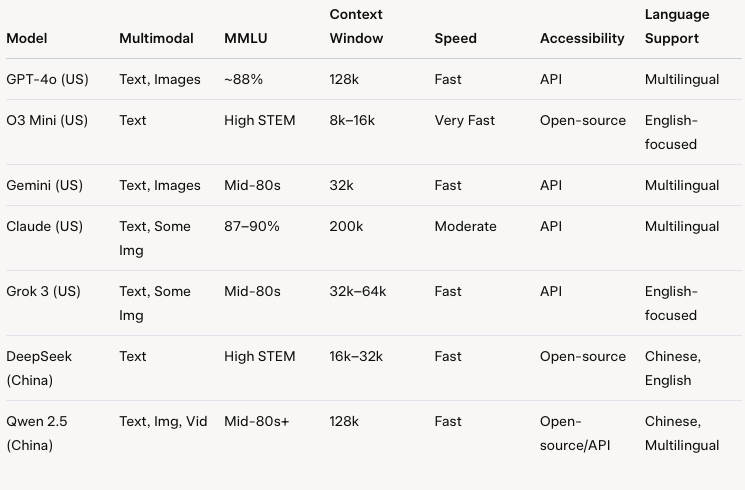
Multimodal Capabilities: GPT-4o handles text, images, and potentially other data types, excelling in tasks like image captioning and text generation from visual inputs.
Performance Benchmarks: Scores high on MMLU (around 88%) and HumanEval (coding tasks), reflecting strong reasoning and technical prowess.
Architecture and Training: Built on a transformer architecture with extensive pre-training and fine-tuning on diverse datasets, though specifics remain proprietary.
Strengths: Versatile, with top-tier reasoning and creative output.
Weaknesses: High computational cost and limited transparency.
Use Cases: Chatbots, content creation, technical support.
Accessibility: Available via OpenAI’s API; not open-source.
Language Support: Robust multilingual capabilities, optimized for English.
Context Window: Estimated at 128k tokens, enabling long conversations.
Response Speed: Fast but varies with API load.
O3 Mini and O3 Mini High (Ollama)
Multimodal Capabilities: Primarily text-focused, with limited multimodal features compared to GPT-4o.
Performance Benchmarks: O3 Mini is optimized for STEM tasks (e.g., math, coding), scoring well on HumanEval; O3 Mini High likely improves on this, though exact figures are sparse.
Architecture and Training: Lightweight transformer-based design, fine-tuned for efficiency and reasoning.
Strengths: Cost-efficient and fast for STEM applications. Weaknesses: Less versatile outside technical domains.
Use Cases: Education, coding assistants.
Accessibility: Open-source options available, broadening access.
Language Support: Strong English focus; multilingual support unclear.
Context Window: Likely smaller, around 8k–16k tokens.
Response Speed: Notably quick due to optimization.

Gemini (Google)
Multimodal Capabilities: Processes text, images, and possibly audio, leveraging Google’s vast data ecosystem.
Performance Benchmarks: Competitive on MMLU (mid-80s) and coding tasks, though specifics depend on the variant.
Architecture and Training: Transformer-based, trained on Google’s extensive web and multimodal data.
Strengths: Seamless integration with Google services. Weaknesses: Performance can lag behind top-tier models in niche tasks.
Use Cases: Search enhancement, multimedia analysis.
Accessibility: API access; not fully open-source.
Language Support: Excellent multilingual support due to Google’s global reach.
Context Window: Estimated at 32k tokens.
Response Speed: Fast, optimized for real-time applications.
Claude (Anthropic)
Multimodal Capabilities: Text-focused, with Claude 3.5 adding some image processing, though less advanced than rivals.
Performance Benchmarks: Matches or exceeds GPT-4o on MMLU (87–90%) and excels in safety and interpretability.
Architecture and Training: Transformer-based, emphasizing safety and alignment with human values.
Strengths: Safe, interpretable outputs. Weaknesses: Limited multimodal scope.
Use Cases: Customer service, ethical AI applications.
Accessibility: API available; not open-source.
Language Support: Strong English, growing multilingual capabilities.
Context Window: Up to 200k tokens, industry-leading.
Response Speed: Moderate, prioritizing accuracy.
Grok 3 (xAI)
Multimodal Capabilities: Likely handles text and some image inputs, though details are emerging.
Performance Benchmarks: Early reports suggest competitive MMLU scores (mid-80s), with a focus on reasoning.
Architecture and Training: Transformer-based, trained to accelerate scientific discovery.
Strengths: Insightful, truth-seeking responses.
Weaknesses: Still maturing, less proven than peers.
Use Cases: Research, education.
Accessibility: API access via xAI; not open-source.
Language Support: Primarily English, expanding gradually.
Context Window: Estimated at 32k–64k tokens.
Response Speed: Fast, designed for efficiency.
Chinese AI Models
DeepSeek LLM
Multimodal Capabilities: Primarily text-based, with emerging multimodal features in variants like DeepSeek-R1.
Performance Benchmarks: Strong on reasoning tasks (e.g., HumanEval), often rivalling US models, though exact MMLU scores vary.
Architecture and Training: Transformer architecture with reinforcement learning and supervised fine-tuning for reasoning.
Strengths: Cost-effective, reasoning-focused.
Weaknesses: Limited multimodal maturity.
Use Cases: Academic research, technical problem-solving.
Accessibility: Open-source options are available, and widely accessible in China.
Language Support: Excellent Chinese support, decent English.
Context Window: Around 16k–32k tokens.
Response Speed: Quick, optimised for efficiency.
Qwen 2.5 (Alibaba)
Multimodal Capabilities: Qwen 2.5-VL excels in text, images, and video, outperforming GPT-4o in some multimodal tasks.
Performance Benchmarks: Surpasses GPT-4o on document analysis and math, with high MMLU scores (likely mid-80s or higher).
Architecture and Training: Scalable transformer design (3B–72B parameters), trained on diverse Chinese and global data.
Strengths: Multimodal excellence, scalability. Weaknesses: Less focus on non-Chinese languages.
Use Cases: E-commerce, video analysis, UI interaction.
Accessibility: Open-source variants; API access via Alibaba.
Language Support: Superior Chinese support, and solid multilingual capabilities.
Context Window: Up to 128k tokens in larger models.
Response Speed: Fast, leveraging Alibaba’s infrastructure.
Comparative Analysis
Multimodal Capabilities
US models like GPT-4o and Gemini lead in integrating text and images, while Claude and O3 Mini lag in multimodal scope. China’s Qwen 2.5 stands out, surpassing GPT-4o in video and document processing, while DeepSeek remains text-centric.
Performance Benchmarks
Both nations boast high performers. GPT-4o and Claude edge out on MMLU, while Qwen 2.5 excels in specialized tasks. O3 Mini and DeepSeek shine in STEM, reflecting a focus on reasoning over breadth.
Architecture and Training
All models rely on transformers, but US models emphasize scale (GPT-4o, Claude), while Chinese models like Qwen 2.5 prioritize multimodal flexibility. DeepSeek’s use of reinforcement learning is a unique twist.
Strengths and Weaknesses
US models offer versatility (GPT-4o, Gemini) and safety (Claude), but at a higher cost. Chinese models provide cost-efficiency (DeepSeek) and multimodal innovation (Qwen 2.5), though they’re less dominant in English-centric tasks.
Use Cases
US LLMs dominate in global applications like chatbots and search, while Chinese models excel in regional strengths—e-commerce for Qwen and research for DeepSeek.
Accessibility and Availability
China’s open-source offerings (DeepSeek, Qwen) contrast with the US’s API-driven approach, though Ollama’s O3 Mini bridges this gap.
Language Support
US models prioritise English with strong multilingual support, while Chinese models excel in Chinese, with Qwen showing broader language potential.
Context Window and Speed
Claude’s 200k token window is unmatched, but Qwen and GPT-4o (128k) compete. Speed favours lightweight models like o3 Mini and DeepSeek.